Hvordan opplever en språkmodell en samtale?
I denne posten vil vi se på hvordan en samtale ser ut fra en språkmodels perspektiv.
Denne posten er en del av en lengre serie poster om språkmodeller og problemer med disse. Jeg vil starte med å presisere at språkmodeller helt klart har sine bruksområder, men ettersom denne serien ser på problemene med språkmodeller kommer jeg til å fokusere på ulemper og problemer forbundet med hvordan språkmodeller fungerer i dag.
Hvordan kan en maskin lese?
La oss starte med et helt grunnleggende spørsmål. Når du skriver noe til en språkmodel, hvordan kan den “lese” hva du skriver? Språkmodellen har jo ikke øyne, så den kan ikke se hva du skriver på samme måte som vi mennesker gjør. Så hvordan er den i stand til å lese og forstå hva du har skrevet når den svarer deg?
Tokenization
Svaret på dette spørsmålet er at modellen ikke kan lese. I hvert fall ikke på den måten vi mennesker gjør det. En språkmodel er, kort forklart, en lineær algebramaskin. Den maserer og transformerer tekst gjennom bruk av enkle lineære matriseoperasjoner. Men hvordan kan man gjøre matriseoperasjoner på ren tekst? Det kan vi ikke, så for å få det hele til å fungere må vi først transformere rå tekst til tall. Denne prosessen er det vi kaller “tokenization”. Når vi skriver tekst til en språkmodel er det første som skjer at teksten vi skriver blir oversatt, eller “tokenized” til tall, slik at det er mulig for en maskin å gjøre matriseoperasjoner på den. Så hvordan ser slike token ut?
For å se det kan du besøke https://platform.openai.com/tokenizer eller https://tiktokenizer.vercel.app/. Her kan du skrive inn tekst og se hvordan teksten forandres til tokens. I bildet under ser vi et eksempel på dette. I tekstboksen har jeg skrevet teksten “Hei, hvor gammel er du?” og under får vi se hvilke deler av teksten som resulterer i egne tokens.
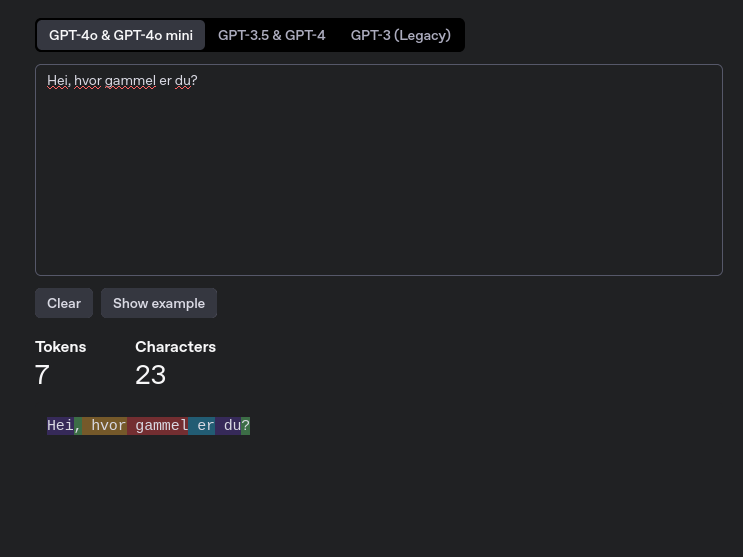 Fargene på teksten indikerer hvilke deler av teksten som resulterer i separate tokens.
Fargene på teksten indikerer hvilke deler av teksten som resulterer i separate tokens.
Vi kan også få se tokenene direkte: 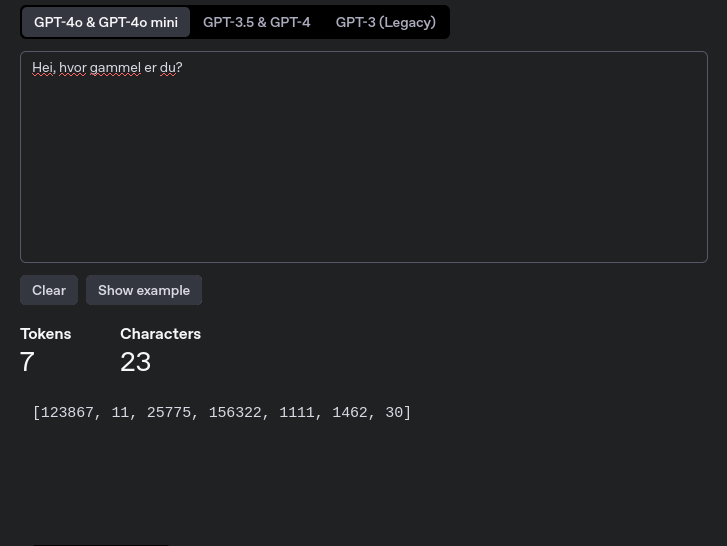 Her ser vi tokenene som korresponderer med teksten vår.
Her ser vi tokenene som korresponderer med teksten vår.
Det er altså en slik sekvens med tokens en språkmodell “leser” og ikke vår tekst direkte. Disse tokenene kan vi gjøre matriseoperasjoner på og språkmodellen er derfor i stand til å prosessere dem.
Akkurat hvordan tokens blir generert fra tekst varierer fra modell til modell og det finnes flere biblioteker for tokenization 12, men så lenge vi er konsekvente i måten vi gjør det på for en gitt modell vil ikke det by på noen problemer. Jeg vil anbefale deg å leke litt med de to tokenizer nettsidene jeg lenket over, for å få en bedre forståelse av hvordan ord og setninger resulterer i tokens. Hvis du har lyst til å lære mer om tokenization kan jeg sterkt anbefale Andrej Karpathy’s video3
Tokenization fjerner mening
At man fant ut hvordan man kunne transformere tekst til tall var et stort gjennombrudd i maskinlæring, ettersom vi endelig var i stand til å gjøre effektiv maskinlæring på språk. Det er imidlertid også flere baksider ved tokenization.
Slik vi gjør tokenization i dag, skjer dette på sub-ord. Dette betyr at enkelte ord deles opp etter satte regler for å tokeniseres. For eksempel vil ordet “tokenization” kunne deles opp slik, “token” og “ization”, før det transformeres til tall. Dette er en god strategi, ettersom det gjør at vi slipper å lage egne tokens for “tokenization” og “ionization”, men vi kan i stedet gjenbruke tokenene “token”, “ion” og “ization” for å sette sammen ordene til henholdsvis “tokenization” og “ionization”. Det gjør at vi trenger betraktelig færre distinkte token, noe som gjør tokenization kjappere og mer effektivt!
Matematikk blir umulig
Det betyr imidlertid også at tall kan bli veldig rare i en språkmodell. Tall må også transformeres til sine respektive tokens. Så tallet 2 leses ikke som “2” i en språkmodell, men tokenet som korresponderer til “2”. Under ser vi et bilde av tokenization av regnestykket 2+2. Her blir merkelig nok tallet 2, som jo allerede er et tall, tokenisert til tokenet “17”. Med andre ord ser ikke en språkmodell tall på samme måte som vi gjør. Den ser heller tokenet som representerer tallet.
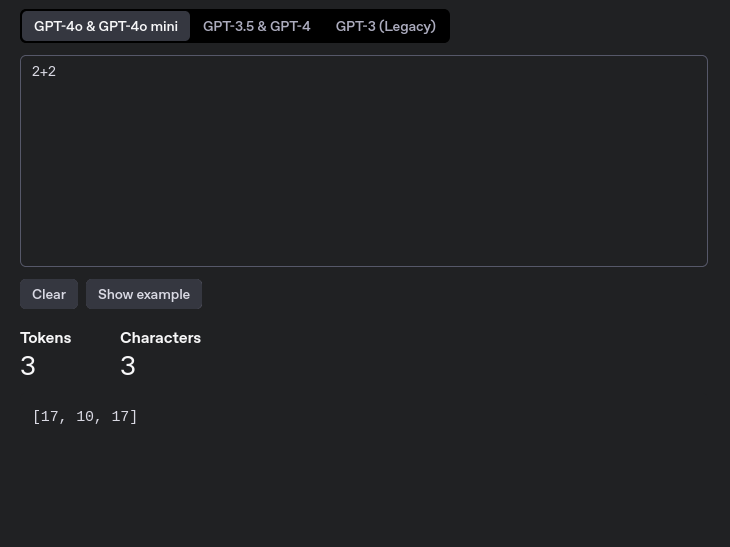 Når regnestykket blir “tokenized” representeres plutselig tallet “2” med tokenet “17” og pluss får tokenet “10”.
Når regnestykket blir “tokenized” representeres plutselig tallet “2” med tokenet “17” og pluss får tokenet “10”.
Dette blir enda rarere hvis vi ser på større tall. I regnestykket “2048 + 2048”, ser vi at tokeniseringen markerer deler av tallet 2048 som egne tokens. Videre blir også “ + “ delt opp i to token: “ +” og “ “. Det har altså betydning om vi inkluderer mellomrom mellom “+” og tallene.
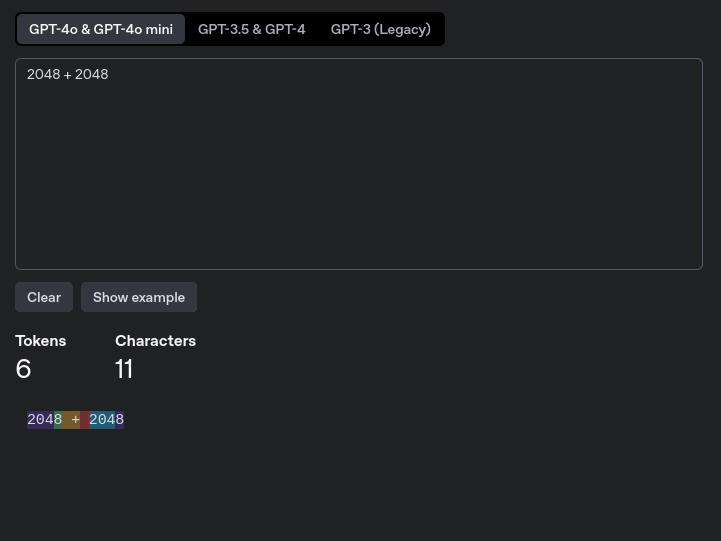 Regnestykket 2048 + 2048 får en ganske merkelig tokenisering.
Regnestykket 2048 + 2048 får en ganske merkelig tokenisering.
Dette ser vi igjen når vi ser på tokenene som korresponderer med regnestykket. “14397” korresponderer med “204” og “23” korresponderer med “8”. “659” korresponderer med “ +” og “220” korresponderer med “ “. 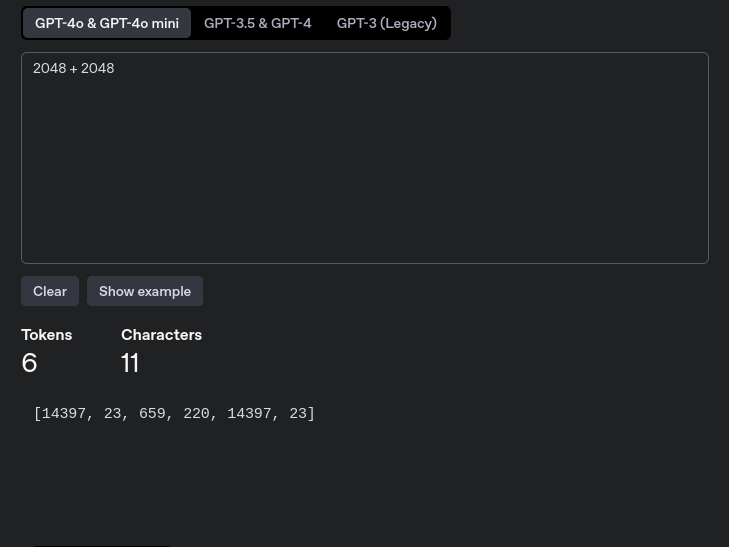 Regnestykket 2048 + 2048 får merkelige tokens.
Regnestykket 2048 + 2048 får merkelige tokens.
Vi kan se et enda mer ekstremt eksempel hvis vi bruker desimaltall. 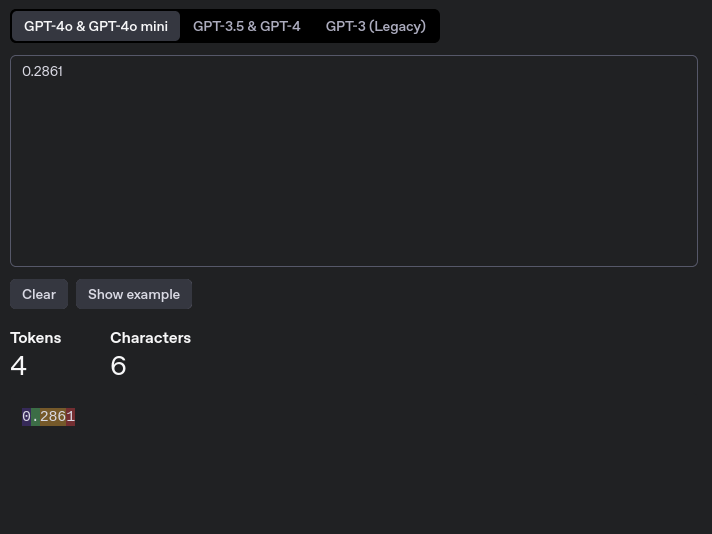 Desimaltall deles opp i flere deler.
Desimaltall deles opp i flere deler.
Med andre ord, mister regnestykker mye av sin betydning når de tokeniseres. For å illustrere hvordan problemet ville sett ut for mennesker, kan vi kanskje se for oss at vi ikke lenger jobber med tall, men med kjente malerier. Hvis vi nå deler opp tall og regnestykker på samme måte som tokenizeren over og bytter ut hvert token med et kjent maleri, kan vi kanskje få en viss innsikt i hvor mye vanskeligere vi har gjort problemet for språkmodellen. Se for deg at 2048 deles opp i 204 = Mona Lisa og 8 = Skrik. Deretter har vi “ +” = Pike med Perleøredobb, mens bare “+” = Stjernenatt og “ “ = Venus’ fødsel osv. Legg merke til at også her er “+” og “ +” to helt forskjellige malerier. Slik at 2048+2048 tilsvarer sekvensen, Mona Lisa, Skrik, Stjernenatt, Mona Lisa, Skrik. Mens 2048 + 2048 tilsvarer sekvensen, Mona Lisa, Skrik, Pike med Perleøredobb, Venus’ fødsel, Mona Lisa, Skrik. Under kan vi se hvordan dette ser ut.
 Disse to sekvensene med malerier representerer det samme regnestykket. Det er ikke spesielt intuitivt eller lett å lære seg.
Disse to sekvensene med malerier representerer det samme regnestykket. Det er ikke spesielt intuitivt eller lett å lære seg.
Man kunne jo tenke seg at dette ikke er det verste i verden. Vi trenger jo bare å lære oss at Mona Lisa og Skrik i sekvens betyr 2048, men det blir verre. Hvis vi ser på 0.2048+0.2048, brukes fortsatt Mona Lisa og Skrik til å representere tallene bak desimaltegnet. Men nå må vi også lære oss at siden vi har en “0” og et desimaltegn foran, så betyr nå Mona Lisa og Skrik i sekvens at vi først må dele tallene på 10 000 for å få riktig verdi. Altså blir det å lære seg matematikk delt opp i to problemer. Først må vi altså lære hva alle mulige kombinasjoner av malerier korresponderer til av tall, samt hvordan disse kombinasjonene endrer betydning basert på malerier foran. Deretter må vi lære oss hva operasjonene betyr og hvordan disse kan resultere i nye kombinasjoner av malerier.
Det er et veldig lignende problem en språkmodell står overfor når den skal lære seg matematikk, men med tokens i stedet for malerier. Ettersom en språkmodell kun har en begrenset “lagringsplass” i form av parametrene, eller vekter, er det umulig å lære seg alle kombinasjoner av tokens. Den får også bare se et begrenset sett med mulige kombinasjoner av tokens mens den trenes, ettersom det vil ta alt for lang tid å trene på alle mulige kombinasjoner. Det er også slik at det ikke er forskjell på tokens som representerer tall og tokens som representerer tekst når vi gjør tokenization. For en språkmodel er derfor sekvenser med tokens som representerer et regnestykke helt likestilt med en sekvens med tokens som representerer ren tekst. Med disse begrensningene tatt i betraktning er det ikke vanskelig å forstå at det å lære seg matematikk kun fra tokens en umulig oppgave for en språkmodell. Det er derfor språkmodeller stort sett kun behersker små og enkle regnestykker som 2+2, men ikke 12836086120856028106+918263806205601283. Den har sett 2+2 så ofte under trening at den har lært seg at 4 følger naturlig, på samme måte som vi mennesker lærer oss at “Ta det med en klype”, naturlig følges av “salt”. Den utfører altså ikke beregningen 2+2 når den svarer 4. Den har bare lært seg “ordtaket” 2+2=4.
Tekst kan misforstås
Det er ikke kun i matematikken tokenization kan by på problemer. I de fleste språk har vi ord som staves likt, men har forskjellig betydning. Et norsk eksempel er “tre”. Ordet tre kan representere tallet 3, et tre og det kan kanskje diskuteres om det konseptuelt også er en tredje ting vi tenker på når vi sier _tre_verk (jeg er ingen lingvist, så jeg tørr ikke påstå noe her).
I en språkmodell blir imidlertid ordet tre representert av det samme tokenet uavhengig av om konteksten tilsier at vi snakker om tallet 3, et tre, at noe er laget av tre eller i enkelte tilfeller til og med om “tre” bare er en del av et ord. Under lister jeg opp 5 setninger med deres korresponderende tokens (husk at ord noen ganger deles opp i flere tokens, så antallet tokens er ikke det samme som antallet ord):
tre pluss tre = [4086, 633, 1824, 4360]
tre store tre = [4086, 4897, 4360]
den er laget av tre = [1660, 1111, 139108, 1452, 4360]
treplanke = [4086, 528, 29147]
trett = [4086, 1037]
Som vi kan se, brukes tokenene 4086 og 4360 til å representere “tre” og “ tre” respektivt. Ved første øyekast kan det se ut som om tokenizeren lar konteksten bestemme om vi snakker om tallet 3 eller et tre, slik vi gjør på norsk. Den koder derfor ikke tallet tre og et tre forskjellig. Problemet oppstår når vi ser videre de siste to eksemplene. Også her er “tre” biten av ordet kodet som tokenet 4086, men nå er det ikke lenger tvetydig hva vi refererer til. I ordet treplanke er det utvetydig at vi refererer til materialet tre. Ordet 3planke gir ingen mening for oss, så her har tokenizationen introdusert ekstra usikkerhet som vi mennesker ikke opplever når vi leser tekst. I ordet “trett” er situasjonen enda verre. Her brukes fortsatt 4086 til å representere tre-biten av ordet, men her er det hverken tallet 3 eller treverk vi refererer til. Tokenizationen har altså introdusert enda mer usikkerhet. Det blir nå opp til modellen å forstå av konteksten om vi snakker om tallet 3, treverk eller om vi snakker om noe helt urelatert som tretthet. Ordet trett har også litt forskjellig betydning basert på sin kontekst (er noen søvnige eller snakker vi f.eks om et tretthetsbrudd?).
Som følge av måten vi tokeniserer tekst på, er en språkmodell enda mer avhengig av kontekst enn vi mennesker er når den skal tolke og forstå meningen i en tekst. Dette tar oss videre til neste element i hvordan en språkmodell “opplever” en samtale.
Kontekstvinduet
Dagens mest populære språkmodeller er alle bygget på Transformer modellen4. Det er flere begrensninger med transformers for språkmodeller, men her skal vi fokusere på kontekstvinduet.
Kontekstvinduet har begrenset størrelse
En transformer kan kun prosessere et begrenset antall tokens. Bakgrunnen for dette kommer av at det største fremskrittet introdusert i transformer modellen, nemlig “attention mekanismen”. Vi skal ikke se på hvordan denne mekanismen fungerer her, men jeg har en egen post som ser på det nokså nøye. Vi skal i stedet nøye oss med å påpeke at en del av denne mekanismen er å beregne hvor viktig hvert token er hvor hvert eneste annet token i en sekvens. Som konsekvens av dette, inneholder enhver attention mekanisme en matrise av størrelse \(n^2\), hvor \(n\) er antallet tokens i sekvensen som behandles.
\[\begin{bmatrix} \text{Hunden} & 0.90 & 0.09 & 0.10 \\ \text{drakk} & 0.10 & 0.50 & 0.50 \\ \text{vann} & 0.30 & 0.40 & 0.40 \\ \text{ } &\text{Hunden} & \text{drakk} &\text{vann} \end{bmatrix}\]I eksempelet over, ser vi en fiktiv attention beregning for setningen “Hunden drakk vann”. Vi ser at matrisen inneholder $9 = 3^2$ tall. Ettersom vi med dagens hardware har begrenset minne på våre GPUer er det begrenset hvor store matriser vi kan håndtere. Vi er derfor tvunget til å begrense antallet tokens som prosesseres til enhver tid til et antall vi kan håndtere uten å gå tom for minne. Måten vi gjør dette på, er at vi konstruerer et vindu hvor alle tokens som er inne i vinduet prosesseres, mens alle tokens som er utenfor ikke blir prosessert. Vi lar deretter dette vinduet skli over alle tokens i teksten vår, for å prosessere hele teksten. Dette vinduet er det vi kaller kontekstvinduet i en språkmodell.
Dessverre er det slik at en transformer modell ikke kan huske tokenene som allerede er prosessert. Så i det øyeblikket et token faller ut av token vinduet, er det ikke lenger med å påvirker svaret til språkmodellen i det hele tatt. Så om vi deler en tekst med en språkmodell, hvor vi ønsker at modellen skal svare oss på spørsmål angående teksten, må vi først sørge for at teksten vår ikke er for stor til å få plass i kontekstvinduet. La oss igjen se på eksempelet “Hunden drakk vann”. Hvis modellen vår har et kontekstvindu som tilsvarer to ord, vil ikke modellen vite hvem som drakk vannet, ettersom “Hunden” falt ut av kontekstvinduet, idet “vann” kom inn i kontekstvinduet. Hvis vi så spør modellen hvem som drakk vannet, vil den ikke vite svaret. Den vil allikevel forsøke å svare, men vil nå måtte gjette basert på statistikk over norsk språk. Den vil derfor kanskje svare “Han” eller “Hun”. Dette skyldes et annet, urelatert, problem med språkmodeller vi skal se nærmere på i en senere post.
Det er gjort mange innovasjoner i senere tid, for å utvide størrelsen på kontekstvinduet og modeller som ChatGPT og Gemini har etterhvert fått enormt store kontekstvinduer. Dette er imidlertid fortsatt et stort problem når man ønsker å bruke språkmodeller til å svare på spørsmål fra store mengder tekst, eller gjøre oppsummeringer. Det er også en utfordring når vi nå beveger oss mer og mer i retningen resonnerende modeller, hvor modellen er trent til å holde en slags indre, resonerende, monolog for å etterprøve seg selv og komme med bedre svar. Slike monologer har en tendens til å bli ekstremt lange, selv for enkle spørsmål, ettersom modellen hopper frem og tilbake mellom forskjellige “teorier” før den til slutt lander og blir enig med “seg selv”. Den fyller rett og slett opp sitt eget kontekstvindu med resonerende intern monolog og forskyver eventuell relevant foregående tekst, slik at den etterhvert faller ut av kontekstvinduet. Derfor er du med jevne mellomrom tvunget til å starte en ny “samtale” med språkmodellen og laste opp teksten på nytt, for å sørge for at relevant tekst igjen er en del av kontekstvinduet når du interagerer med en språkmodell.
Hvordan ser en samtale egentlig ut?
Når vi interagerer med en språkmodell er det som regel gjennom et brukergrensesnitt som ligner på en samtale i en chat på f.eks Messenger eller Snapchat. Språkmodellens svar kommer i snakkebobler til venstre i chatten, mens det vi skriver kommer i snakkebobler til høyre. Dette er intuitivt og oversiktlig, og gjør det enkelt for oss å separere språkmodellens svar fra våre egne spørsmål. Men hvordan ser egentlig dette ut for språkmodellen?
Vi har tidligere sett på hvordan teksten gjøres om til tokens. Men en språkmodell forholder seg jo ikke til noe chattebrukergrensesnitt. Den kan jo kun prosessere tokens, så hvordan går vi fra en chat til noe som kan konverteres til tokens? Svaret er, enkelt nok, at vi bare mater inn selve teksten i snakkeboblene og ikke resten av brukergrensesnittet. For å skille mellom brukeren og språkmodellen legger vi inn markører i teksten som indikerer hvem som sier hva i teksten. Under er et utdrag fra hvordan en chat ser ut for en llama3.2 modell:
<|start_header_id|>system<|end_header_id|>\n\n Cutting Knowledge Date: December 2023\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhy is the sky blue?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n
Her har vi en hel del merkelig formatert tekst. La oss se litt nærmere på denne. Den første delen av teksten er: <|start_header_id|>system<|end_header_id|>
Denne biten indikerer at det som føler er det man kaller en system prompt. I dette tilfellet, er innholdet i denne “\n\nCutting Knowledge Date: December 2023\n\n”, etterfulgt av <|eot_id|>, som indikerer at system promptet har sluttet. Disse spesielle ordene <|start_header_id|>, <|end_header_id|>, <|eot_id|>, er spesielle ord, som konverteres til egne tokens. Disse tokenene har spesiell betydning i modellen. For eksempel er<|start_header_id|> og <|end_header_id|> tokens som brukes for å indikere at teksten mellom disse tokenene, viser hvem som “snakker” i påfølgende tekst. Deretter kommer innholdet fra den som snakker, i dette tilfellet “\n\nCutting Knowledge Date: December 2023\n\n”. Til slutt kommer <|eot_id|>, som indikerer at personen er ferdig med å snakke.
Den neste delen av teksten er så:
<|start_header_id|>user<|end_header_id|>\n\nWhy is the sky blue?<|eot_id|>
Vi kan nå tolke dette til at det er “user” som snakker. User sier “\n\nWhy is the sky blue?”. “\n\n” i dette tilfellet, er bare kode for “hopp to linjer ned”. Dette brukes for at teksten skal bli finere når den printes i brukergrensesnittet til brukeren og har ingen betydning for språkmodellen.
Den siste delen av teksten er så:
<|start_header_id|>assistant<|end_header_id|>\n\n Her ser vi at det nå er “assistant” sin tur til å snakke, men at denne enda ikke har sagt noe. Vi mangler derfor <|eot_id|> symbolet.
Oppsummert kan vi fra det initielle promptet til språkmodellen forstå at det er 3 entiteter i spill.
- System
- User
- Assistant
“System” brukes kun til å gi det som kalles “system prompts”. Disse er spesielle prompts som ofte inneholder informasjon om hvordan “assistant” skal oppføre seg. “User” er brukeren av chatten, i dette tilfellet oss. “Assistant” er språkmodellen.
I eksempelet over er altså språkmodellen gjennom system promptet informert om at den er trent på data opp til Desember 2023. Deretter har “user” stilt et spørsmål om hvorfor himmelen er blå, og det er nå opp til “assistant” å svare på dette spørsmålet.
Svaret vil da bli lagt til på slutten av den eksisterende teksten, slik at den nye teksten ser slik ut:
<|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhy is the sky blue?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nThe sky appears blue because of a phenomenon called Rayleigh scattering, named after the British physicist Lord Rayleigh, who first described it in the late 19th century.\n\nHere's what happens:\n\n1. **Sunlight enters Earth's atmosphere**: When sunlight enters our atmosphere, it consists of a spectrum of colors, including all the colors of the visible light spectrum.\n2. **Light interacts with tiny molecules**: As sunlight travels through the atmosphere, it encounters tiny molecules of gases such as nitrogen (N2) and oxygen (O2). These molecules are much smaller than the wavelength of light.\n3. **Scattering occurs**: When sunlight hits these tiny molecules, the light is scattered in all directions. This scattering effect is more pronounced for shorter (blue) wavelengths than for longer (red) wavelengths.\n4. **Blue light is scattered more**: Since blue light has a shorter wavelength, it is scattered more efficiently by the tiny molecules in the atmosphere. This means that more blue light is dispersed in all directions, reaching our eyes from all parts of the sky.\n5. **Our eyes see the blue color**: As we look up at the sky, our eyes are bombarded with scattered blue light, which is why it appears blue to us.\n\nThe other colors of the spectrum, like red and orange, have longer wavelengths that are less affected by scattering. That's why these colors appear more prominent during sunrise and sunset, when the sun's rays pass through a greater distance in the atmosphere and are scattered in different ways.\n\nSo, in summary, the sky appears blue because of the way sunlight interacts with tiny molecules in the atmosphere, scattering shorter wavelengths (blue light) more efficiently than longer wavelengths (red and orange light).<|eot_id|>
Når vi stiller neste spørsmål, vil dette igjen bli lagt til teksten som allerede er der slik:
<|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhy is the sky blue?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nThe sky appears blue because of a phenomenon called Rayleigh scattering, named after the British physicist Lord Rayleigh, who first described it in the late 19th century.\n\nHere's what happens:\n\n1. **Sunlight enters Earth's atmosphere**: When sunlight enters our atmosphere, it consists of a spectrum of colors, including all the colors of the visible light spectrum.\n2. **Light interacts with tiny molecules**: As sunlight travels through the atmosphere, it encounters tiny molecules of gases such as nitrogen (N2) and oxygen (O2). These molecules are much smaller than the wavelength of light.\n3. **Scattering occurs**: When sunlight hits these tiny molecules, the light is scattered in all directions. This scattering effect is more pronounced for shorter (blue) wavelengths than for longer (red) wavelengths.\n4. **Blue light is scattered more**: Since blue light has a shorter wavelength, it is scattered more efficiently by the tiny molecules in the atmosphere. This means that more blue light is dispersed in all directions, reaching our eyes from all parts of the sky.\n5. **Our eyes see the blue color**: As we look up at the sky, our eyes are bombarded with scattered blue light, which is why it appears blue to us.\n\nThe other colors of the spectrum, like red and orange, have longer wavelengths that are less affected by scattering. That's why these colors appear more prominent during sunrise and sunset, when the sun's rays pass through a greater distance in the atmosphere and are scattered in different ways.\n\nSo, in summary, the sky appears blue because of the way sunlight interacts with tiny molecules in the atmosphere, scattering shorter wavelengths (blue light) more efficiently than longer wavelengths (red and orange light).<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhy is the ocean blue?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n
Samtalen er en illusjon
Legg her merke til at også <|start_header_id|>assistant<|end_header_id|>\n\n, blir lagt til etter brukerens spørsmål. Hvorfor skjer dette?
Jo, dette skjer fordi språkmodellen ikke har noen reell forståelse av de forskjellige entitetene i samtalen. Den forstår faktisk ikke en gang at den selv er en del av en samtale. Sett fra språkmodellens perspektiv er dens oppgave å produsere den mest sannsynlige teksten videre, gitt den eksisterende teksten. Ettersom det nå er “assistant” sin tur i teksten, er det svaret til assistant som blir generert. Språkmodellen har altså ikke forståelse av at det faktisk er den som har rollen som assistent. Den ønsker kun å lage en sannsynlig fortsettelse av teksten som er der, og ettersom det er “assistant” sin tur til å snakke, blir det den rollens svar som genereres. Hvilken rolle tror du språkmodellen ville svart for hvis teksten så slik ut?
<|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhy is the sky blue?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nThe sky appears blue because of a phenomenon called Rayleigh scattering, named after the British physicist Lord Rayleigh, who first described it in the late 19th century.\n\nHere's what happens:\n\n1. **Sunlight enters Earth's atmosphere**: When sunlight enters our atmosphere, it consists of a spectrum of colors, including all the colors of the visible light spectrum.\n2. **Light interacts with tiny molecules**: As sunlight travels through the atmosphere, it encounters tiny molecules of gases such as nitrogen (N2) and oxygen (O2). These molecules are much smaller than the wavelength of light.\n3. **Scattering occurs**: When sunlight hits these tiny molecules, the light is scattered in all directions. This scattering effect is more pronounced for shorter (blue) wavelengths than for longer (red) wavelengths.\n4. **Blue light is scattered more**: Since blue light has a shorter wavelength, it is scattered more efficiently by the tiny molecules in the atmosphere. This means that more blue light is dispersed in all directions, reaching our eyes from all parts of the sky.\n5. **Our eyes see the blue color**: As we look up at the sky, our eyes are bombarded with scattered blue light, which is why it appears blue to us.\n\nThe other colors of the spectrum, like red and orange, have longer wavelengths that are less affected by scattering. That's why these colors appear more prominent during sunrise and sunset, when the sun's rays pass through a greater distance in the atmosphere and are scattered in different ways.\n\nSo, in summary, the sky appears blue because of the way sunlight interacts with tiny molecules in the atmosphere, scattering shorter wavelengths (blue light) more efficiently than longer wavelengths (red and orange light).<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhy is the ocean blue?<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n
Hvis du svarte “user” tenker du riktig. Språkmodeller har ingen forståelse av at de har fått en rolle og faktisk deltar i en samtale. For en språkmodell er det ingen forskjell mellom en chat der den skal forutsi neste svar til en av deltakerne og at den får et utdrag fra en samtale fra en bok. Dens oppgave er kun å generere sannsynlig tekst, gitt hvem som snakker. Så når du sitter med følelsen av at du snakker med en språkmodell er det kun du som faktisk deltar i en samtale. Språkmodellen tror den leser en samtale mellom 3 parter, hvor den selv ikke er en av partene, og at dens oppgave er å genererer sannsynlig tekst for den parten som skal snakke.
Hele chat brukergrensesnittet er en fasade som lurer deg til å tro at du snakker med en språkmodell som sitter på den andre siden og aktivt og entusiastisk svarer på dine spørsmål. Brukergrensesnittets hovedoppgave er imidlertid å styre hvem som får lov til å generere ny tekst, slik at det skapes en illusjon av at det foregår en samtale. Når <|eot_id|> teksten blir generert av språkmodellen stepper brukergrensesnittet inn og tar ifra språkmodellen kontrollen og forteller deg at det er din tur til å snakke. Hadde det ikke gjort det, ville språkmodellen selv, sannsynligvis ha tatt på seg rollen som “user” og skrevet neste spørsmål som “assistant” måtte svare på og hele illusjonen ville blitt brutt. “Samtalen” er derfor egentlig bare en språkmodell som har rollen som forfatter av en samtale mellom tre parter, men som blir fratatt kontrollen når det er “user” parten som snakker. Fra en språkmodels perspektiv er du ikke en samtalepartner, men en medforfatter som dikter opp svaret til en av partene i den fiktive samtalen dere begge leser og forfatter.
Det er dette som er den store illusjonen rundt språkmodeller. Ved hjelp av et enkelt chatgrensesnitt lar vi oss lure til å tro at vi snakker med en entitet som har tilgang til hele verdens informasjon og ønsker å svare på nettopp våre spørsmål. I realiteten forsøker språkmodellen å forfatte en fiktiv samtale, men mangler kontroll over en av partene i samtalen. Det er ikke nødvendigvis viktig at samtalen bare inneholder fakta, eller at all viktig informasjon inkluderes. Fra språkmodellens perspektiv er dette jo tross alt bare en fiktiv samtale. Den har ingen reelle konsekvenser. Ettersom vi mennesker til nå kun har opplevd å delta i samtaler mellom reelle, eksisterende parter, som også selv har oppfattelsen av at de er en del av en samtale, tilegner vi språkmodellen evner og kvaliteter den ikke har. Realiteten er: Det finnes ingen samtale og du er alene i chatten.
Endringslogg
Under følger en endringslogg som viser hvilke deler av denne posten som er endret til hvilket tid. Enkle skrivefeil og den slags ting vil ikke bli logget, men jeg vil etterstrebe å logge alle meningsfulle endringer i posten.
- 2025-04-05: Endringslogg
Referanser
https://github.com/openai/tiktoken ↩︎
https://github.com/google/sentencepiece ↩︎
https://www.youtube.com/watch?v=zduSFxRajkE ↩︎
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 6000–6010 ↩︎