Hvordan svarer en språkmodell?
I denne posten vil vi se på hvordan en språkmodel er i stand til å skrive tekst
Denne posten er en del av en lengre serie poster om språkmodeller og problemer med disse. Jeg vil starte med å presisere at språkmodeller helt klart har sine bruksområder, men ettersom denne serien ser på problemene med språkmodeller kommer jeg til å fokusere på ulemper og problemer forbundet med hvordan språkmodeller fungerer i dag.
Hvordan kan en model skrive?
Tidligere i denne serien har vi sett på hvordan språkmodeller kan lese tekst. I denne posten skal vi se nærmere på hvordan de kan gjøre det motsatte. Nemlig hvordan de genererer tekst.
Som vi har sett tidligere, opererer ikke språkmodeller på tekst direkte, men på tokens. Det er nemlig i token universet en språkmodel lever. Så når en språkmodel skriver tekst, er det ikke egentlig tekst den skriver, men tokens. Vi bruker bare den samme teknikken vi brukte for å tokenize vår tekst i utgangspunktet, til å reversere prosessen for å konvertere språkmodellens tokens til tekst vi kan lese. Men hvordan vet språkmodellen hvilke tokens den skal skrive?
For å svare på det, må vi se nærmere på hvordan man trener språkmodeller. Dagens språkmodeller trenes vanligvis i tre steg.
- Pre-training
- Fine-tuning
- Reinforcement Learning from Human Feedback
Pre-training
La oss starte med pre-training. I dette steget er målet å skape en språkmodell som har god generell forståelse for språk. Vi ønsker å bygge en modell, som skjønner både semantikk og syntaks i språket den trenes i. Det er fortsatt usikkert om dagens modeller faktisk har god forståelse av semantikken i språket (det er nok på et mer metafysisk plan), men syntaksen har man i dag i stor grad mestret. Så hvordan bygger vi slike pre-trained, eller foundation modeller i dag?
Next token prediction
Så og si alle språkmodeller som brukes i dag, pre-traines med en teknikk som kalles next token prediction. I denne settingen er målet for modellen å forutsi hva neste token i en setning, eller sekvens med tekst skal være, gitt de foregående tokenene. For enkelhets skyld, vil jeg i den resterende teksten bruke ord i stedet for tokens. Dette er en forenkling med minimal betydning i denne sammenhengen, men se min tidligere blogpost for en forklaring på hvorfor dette ikke gjelder generelt.
Så språkmodellen kan da for eksempel få setningen “Det er bedre med en fugl i hånden enn ti på”, hvor oppgaven er å forutsi hva neste ord skal være. I dette tilfellet “taket”. Modellen mates med millioner av slike tekstsekvenser, hentet fra hele internett, og den blir hele tiden bedt om å forutsi neste ord. Tanken bak dette er at hvis en modell etter hvert blir god på å forutsi det neste ordet, så betyr det også at den har lært fundamentale deler av et språk. For eksempel, hvis modellen får sekvensen: “Hunden drakk vann. Den som drakk vann var”, så kreves det at modellen forstår at å drikke er verbet, at hunden er subjektet og at vann er objektet. Deretter må den bruke denne informasjonen for å “skjønne” at det manglende ordet i neste setning er “hunden”. God prestasjon i next token prediction krever altså at modellen til en hvis grad lærer språk.
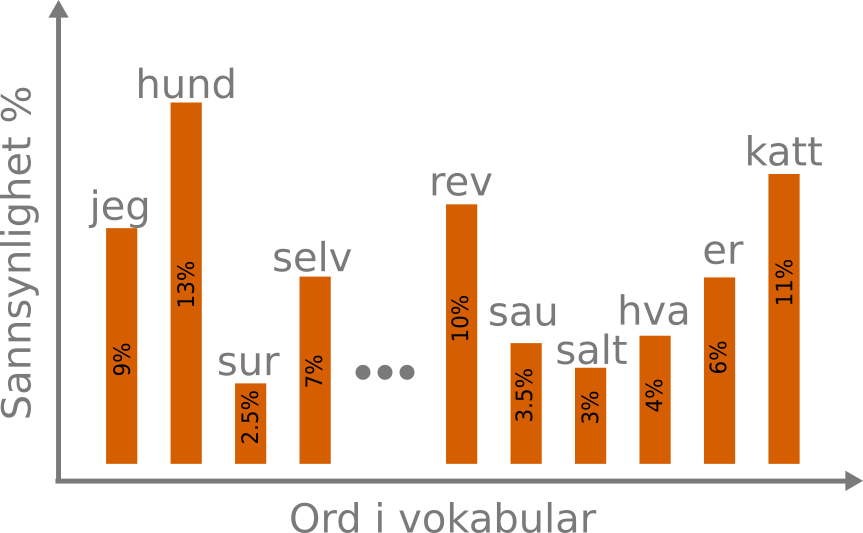 Her ser vi et eksempel på en sannsynlighetsfordling over ordene i et vokabular. Vokabularet er større enn det vi ser her (indikert med de tre prikkene). Hvis man summerer sannsynlighetsprosenten i alle stolpene, inkludert dem vi ikke ser i figuren, vil vi få 100%.
Her ser vi et eksempel på en sannsynlighetsfordling over ordene i et vokabular. Vokabularet er større enn det vi ser her (indikert med de tre prikkene). Hvis man summerer sannsynlighetsprosenten i alle stolpene, inkludert dem vi ikke ser i figuren, vil vi få 100%.
Okay, greit. Men hvordan velger den hvilket ord som skal være det neste ordet? Jo, språkmodellen er utstyrt med et vokabular fra starten av. Dette vokabularet endrer seg ikke i løpet av treningen. I realiteten består vokabularet av tokens, og det vil derfor være mulig for modellen å bygge ord bestående av flere tokens, men dette er en digresjon. For hvert neste ord den skal forutsi må den velge blant ordene i dette vokabularet. Måten den gjør det på er å lage en sannsynlighetsfordeling over alle ordene i vokabularet sitt. Du kan se for deg at modellen lager et stolpediagram, der hver stolpe korresponderer med ett av ordene i modellens vokabular. Høyden på alle stolpene skal summere til 100% (eller 1.0 om du vil). Det ordet med høyest prosentverdi er det ordet som blir valgt (dette er forøvrig også en sannhet med modifikasjoner vi skal komme tilbake til). Et eksempel på en slik fordeling ser vi i figuren over. Når modellen trenes med next token prediction, lærer den egentlig hvordan den skal allokere prosentandeler til hvert ord i vokabularet sitt.
Altså lærer egentlig en språkmodell en sannsynlighetsfordeling over ord i språket, gitt de foregående ordene i en sekvens, når vi gjør next token prediction. Sannsynligheten blir informert av modellens forståelse for språket generelt og innholdet i kontekstvinduet. Så målet med next token prediction er egentlig at modellen skal lære seg riktig sannsynlighetsfordeling over vokabularet sitt, gitt kontekstvinduet. Dette er naturligvis en utrolig vanskelig oppgave, så for å til dette må vi bygge store modeller som trenes på milliarder av ord, men til slutt ender vi opp med en modell som faktisk er nokså god på denne oppgaven.
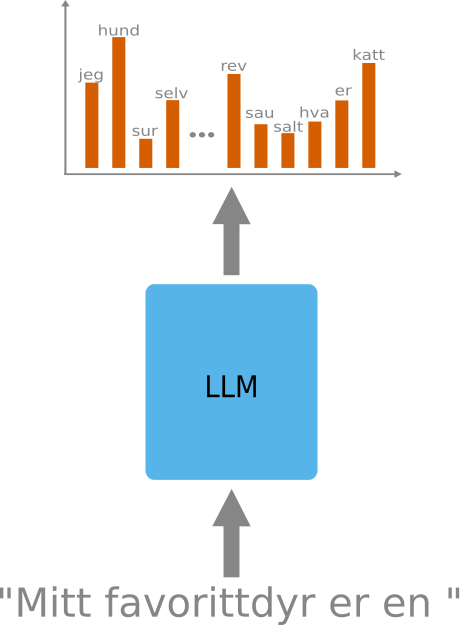 Vi mater en språkmodell (LLM) med tekst, og dens oppgave er nå å forutsi neste ord i teksten. Modellen lager en sannsynlighetsfordeling over ord, og det mest sannsynlige ordet blir valgt.
Vi mater en språkmodell (LLM) med tekst, og dens oppgave er nå å forutsi neste ord i teksten. Modellen lager en sannsynlighetsfordeling over ord, og det mest sannsynlige ordet blir valgt.
Autoregressiv språkmodellering
Okay, så modellen kan forutsi neste ord i en sekvens, men hvordan kan vi gå derfra til å bygge hele setninger eller enda lengre svar? Jo, for å få til det gjør vi et ganske enkelt, men veldig effektivt grep. For hvert nye ord som blir generert av modellen, så limer vi det bare på enden av sekvensen vi matet inn i modellen i forrige steg. Da får vi en ny sekvens, med ett nytt ord. Vi mater så denne nye sekvensen inn i språkmodellen for å få den til å forutsi neste ord der igjen. Vi gjentar dette helt til modellen velger et spesielt “avslutt tekst” ord som det mest sannsynlige ordet. På den måten kan modellen generere lange avhandlinger med intern konsistens og mening. La oss se hvordan det ser ut, ved å bruke et eksempel fra llama3.2 igjen. Husk at llama3.2 bruker spesielle tokens for å markere hvem som snakker når og når de er ferdige med å snakke i en tekst. Under ser vi en tekst som er i ferd med å genereres av en språkmodell:
<|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nHvorfor er hunder alltid så glade?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nHunder er glade fordi
For å finne neste ord i denne teksten ser språkmodellen på hele den foregående teksten. Siden den akkurat har skrever “fordi” er det svært høy sannsynlighet for at neste token er et mellomrom. Modellen vil altså gi ut “ “ som mest sannsynlige neste token, som vi ser i figuren over. Dette legges så på den eksisterende teksten. Deretter mates hele den nye teksten inn i modellen på nytt for at den skal finne neste or igjen:
<|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nHvorfor er hunder alltid så glade?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nHunder er glade fordi
Nå er kanskje det mest sannsynlige neste ordet “de”. Modellen spytter derfor ut “de” og vi legger dette til teksten:
<|start_header_id|>system<|end_header_id|>\n\nCutting Knowledge Date: December 2023\n\n<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nHvorfor er hunder alltid så glade?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\nHunder er glade fordi de
Nå er igjen “ “ det mest sannsylige neste ordet. Så modellen velger “ “ og det blir lagt til teskten. Slik fortsetter det helt til modellen velger <|eot_id|> som mest sannsynlige token.
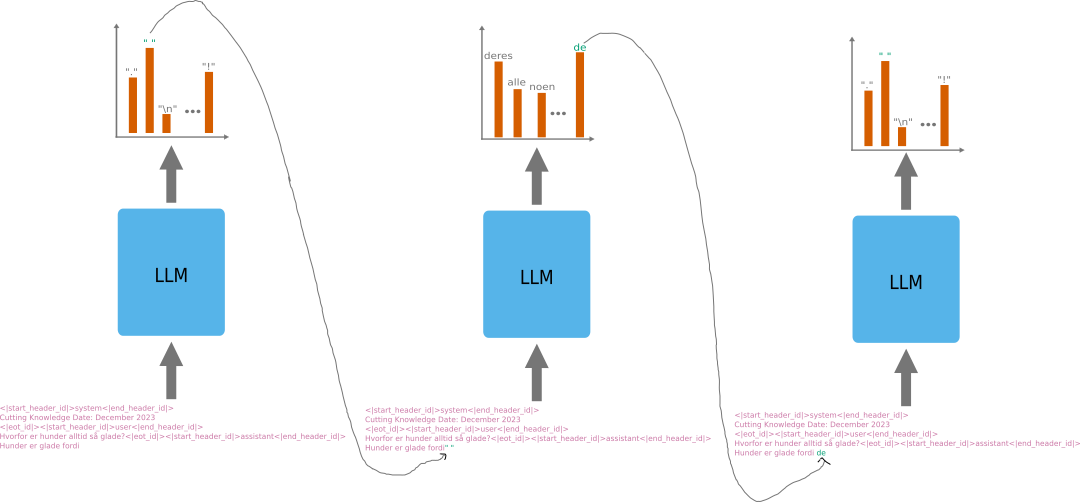 Språkmodellen mates med tekst. Gitt teksten, blir “ “, valgt og dette legges til teksten slik at modellen bruker denne nye teksten for å forutsi neste ord igjen, som nå blir “de”. Slik fortsetter det.
Språkmodellen mates med tekst. Gitt teksten, blir “ “, valgt og dette legges til teksten slik at modellen bruker denne nye teksten for å forutsi neste ord igjen, som nå blir “de”. Slik fortsetter det.
Det fine med dette er at prosessen med å lage arbitrært lange sekvenser med ord er svært enkel og styres av modellen. Men det er også en ganske stor ulempe. Denne prosessen krever at hele teskten må mates gjennom modellen for hvert eneste ord som skal genereres. Som jeg nevnte tidligere, kreves det store modeller for å få en god forståelse av språk. Store modeller krever også mye energi ettersom det er mye regnekraft som må til for å beregne alle operasjonene som skjer inne i modellen. At vi nå krever at hele modellen må kjøres på hele sekvensen med ord, hver gang vi skal generere et nytt ord, betyr at språkmodeller i dag er enorme energisluk. Heldigvis forskes det på hvordan vi kan bruke teknikker som speculative decoding 1 for å kunne generere flere ord på en gang, men vi er fortsatt langt unna å kunne kalle språkmodeller effektive, når det kommer til behov for regnekraft og energi.
En annen interessant observasjon vi kan gjøre oss her er at det eneste som muliggjør at modellen velger sannsynlige neste ord i en tekst er at den får hele teksten matet inn på nytt hver gang. Vi kunne f.eks. ikke bare matet inn det forrige ordet for å få neste ord. Modellen har altså ingen intern “tilstand” eller “state” den vedlikeholder. At modellen fremstår sammenhengende og konsekvent når den svarer oss er egentlig bare en illusjon som skapes av at brukergrensesnittet mater all den foregående teksten inn i modellen for hvert ord som skal genereres. Modellen kan egentlig sees på som en maskin på litt samme måte som en enkel kalkulator. En kalkulator er konsekvent innad i utregningene sine, men den husker ikke hva den har regnet ut tidligere. For at den skal kunne bruke svaret fra forrige utregning i et nytt regnestykke må vi skrive det inn for den.
En annen effekt av denne treningen er at modellen alltid vil foreslå et neste, mest sannsynlige token. Når vi mater den en tekst, vil den ikke være i stand til å ikke svare, fordi den faktsik må velge et neste token. Det finnes ikke et valg som er tomt. Det er derfor vi ser at språkmodeller alltid svarer deg uansett hva du skriver til den. Du kan for eksempel skrive “Ikke skriv noen flere svar”. Og den vil svare med noe sånt som “Forstått, jeg skal slutte å svare”, istedet for å ikke svare deg. Det er rett og slett umulig for en språkmodell å holde kjeft.
Innretting/preferansetrening (engelsk: Alignment)
Etter vi har gjort next token prediction trening med milliarder av ord har vi forhåpentligvis fått en god modell for språk, eller språkmodell som de er mer kjent som. Denne modellen er imidlertid ikke spesielt god til å følge instruksjoner, som å svare på spørsmål eller utføre oppgaver som å lage en oppsummering av tekst. De er heller ikke så høflige og imøtekommende som vi gjerne ønsker at en slik modell skal være.
For å rette på dette må vi trene modellen til å oppføre seg slik vi ønsker. Vi trenger derfor enda et treningssteg. I dette steget er målet å trene modellen til å forstå menneskelige preferanser og innrette seg etter disse. Det finnes flere måter å gjøre dette på og det er kanskje det området det forskes mest på når det kommer til forskning på språkmodeller i dag 23. Jeg tenker alikevell at vi kan se på en av de tradisjonelle måtene dette ble gjort på da den opprinnelige ChatGPT og de andre førstegenerasjons mainstream språkmodellene ble laget: fine-tuning + RLHF.
Fine-tuning
For at modellen vår skal lære seg hvordan den følger instruksjoner og svarer på spørsmål, må vi demonstrere for den hvordan vi ønsker at den skal gjøre det. I fine-tuning steget trener vi modellen på kuraterte eksempler som inneholder spørsmål og svar og oppgaveløsning i noen tusen til millioner eksempler. Det vi gjør her, er at vi gir modellen f.eks. et spørsmål, men ikke svaret, og så trener vi den slik at den gir oss nøyaktig det svaret vi ønsker. Effekten av dette er at modellens forståelse for hva som er mest sannsynlige neste ord, skiftes mot et spørsmål-svar- og oppgaveløsningsparadigme, samt mot et mer høflig og imøtekommende valg av ord. Fine-tuning gir oss grovt sett en mer likandes modell som har lært seg spørsmål-svar struktur. Det er imidlertid fortsatt ikke gitt at modellen har lært seg hvilke verdier vi mennesker foretrekker eller hvordan vi vurderer enkelte svar som bedre enn andre. For å lære modellen etter kan vi bruke enda et steg.
Reinforcement Learning from Human Feedback (RLHF)
Her lar vi språkmodellen generere mange alternative svar til det samme spørsmålet. Vi lar deretter et menneske rangere alle svarene. Vi kan da trene modellen slik at den genererer svar som ender høyt i slike rangeringer. Dette tar naturligvis veldig lang tid når vi skal lage mange slike treningseksmepler, ettersom mennesket må lese og rangere mange svar. For å få dette til å gå fortere kan vi isteden trene en annen språkmodell til å etterligne valgene til mennesket. Når denne etterligningsmodellen er i stand til å etterligne menneskelige valg godt nok, kan vi så bruke denne til å rangere svar generert fra den første fine-tunede språkmodellen.
Tanken her er at etterligningsmodellen lærer seg hva mennesker liker i svar fra språkmodeller og derfor kan gjøre tilsvarende rangeringer på nye spørsmål og svar samlinger. Vi kan da bytte ut mennesket med etterligningsmodellen når vi trener den fine-tunede språkmodellen. Ettersom vi kan lage tusenvis av kopier av etterligningsmodellen kan vi nå få treningsprosessen til å gå fort nok til at vi kan trene språkmodellen vår til å generere svar som mennesker liker og verdsetter. Legg også merke til at dette steget ikke lenger vurderer svarene ord-for-ord, men hele svaret. Altså er det først her innholdet i hele svaret vurderes helhetlig.
I nyere modeller slår man ofte sammen fine-tuning og RLHF stegene i ett steg som optimerer for begge samtidig.
Etter alignment steget har vi en modell som:
- har god forståelse av språk (pre-training) -svarer på spørsmål og følger instruksjoner på en måte som stemmer godt med menneskelige preferanser (alignment)
Vi har nå faktisk fått den modellen som ligger bak alle språkmodeller vi har idag. Det som i størst grad skiller disse modellene fra hverandre er hvilke data de er trent på, hvor lenge de er trent, hvordan alignment gjøres og enkelte forskjeller i den underliggende modellarkitekturen. Men i grove trekk kan vi si at dette er oppskriften på å lage en god språkmodell i dag. Det var jo egentlig ganske enkelt. Ja kanskje for enkelt? La oss se på noen av utfordingene vi opplever med modeller trent på denne måten.
Vi velger ikke alltid det mest sannsynlige ordet
Tidligere sa jeg at det at modellen velger det ordet med høyest prosentverdi når den forutsier neste ord i en sekvens. Det er en sannhet med modifikasjoner. La oss se nærmere på dette. Et problem med å velge det mest sannsynlige ordet hver gang, er at vi ofte ender opp med svar av lav kvalitet og gjenntakende tekst. Du kan teste dette ved å sette temperaturen til en språkmodell til 0.0. For å omgå dette gjør man i dag et probabilistisk utvalg blant det mest sannsynlige ordene. En av de mest vanlige metodene for dette kalles temperature sampling 4.
Vanligvis beregnes sannsynligheten for hvert ord \(x_i\) ved hjelp av en softmax operasjon: \eqref{eq:softmax}. Vi tvinger altså summen av alle sannsynlighetene til å bli 1.0.
\[\begin{equation} \text{softmax}(x_i) = \frac{e^{x_i}}{\sum^n_{j=1}e^{x_j}} \label{eq:softmax} \end{equation}\]I temperature sampling legger vi til en ekstra parameter $\tau$ i denne ligningen, slik at vi får ligningen \eqref{eq:temperature-sampling}. \(\begin{equation} \text{softmax}(x_i) = \frac{e^{x_i/\tau}}{\sum^n_{j=1}e^{x_j/\tau}} \label{eq:temperature-sampling} \end{equation}\)
Ved å sette $\tau > 1.0$ får vi en “mykere” sannsynlighetsfordeling, som igjen gir større sannsynlighet for å velge et annet ord enn det mest sannsynlige. Dette fører til at vi får mer diverse og interessante svar fra modellen ettersom vi introduserer enkelte mindre sannsynlige ord i setningene som genereres. Siden vi gjør autoregressiv generering av tekst fører dette til at retningen setningen beveger seg i forandres litt hver gang vi genererer et nytt ord. Dette forklarer hvorfor en språkmodell sjeldent gir ord for ord, samme svar på et identisk spørsmål.
Divergens, divergens, divergens
Dette er imidlertid også en av forklaringene på hvorfor en språkmodell kan rote seg bort i helt feil svar en gang man stiller et spørsmål, men gi riktig svar, hvis man starter en ny samtale og stiller samme spørsmål. Siden vi noen ganger velger et annet ord enn det mest sannsynlige ordet, sett fra språkmodellens perspektiv, kan vi endre hele betydningen av det modellen “prøver” å svare. Vi kan se på det slik:
- For hvert nye ord vi skal forutsi, velger vi det riktige ordet med en sannsynlighet \(S\) og et annet ord med sannsynlighet \(1-S\). \(S\) styres av vår spesifikke metode for valg av ord fra modellens sannsynlighetsfordeling og hvor god denne sannsynlighetsfordelingen er.
- Hver gang vi velger et annet ord enn det riktige ordet, endrer vi “retningen” en setning tar i større eller mindre grad bort fra den riktige setningen.
- Ettersom vi mater den nye setningen inn i språkmodellen for at den skal forutsi neste ord igjen, vil endringen i retning fra steg 2. også påvirke hvordan sannsynlighetsfordelingen for dette ordet vil se ut. Altså er dette en feedback loop.
- Ettersom modellen er autoregressiv, så kan den ikke gå tilbake og rette opp en tidligere feil. Den er rett og slett tvunget til å fortsette å generere ord basert på den setningen den allerede har skrevet.
Har vi vært uheldig med tidligere ord i setningen vår, vil vi kunne få veldig rare svar i et forsøk, men helt rimelige svar i det neste. Denne effekten, der språkmodellen kan gi vidt forskjellige svar, gitt nøyaktig samme utgangspunkt kaller vi divergens.
Hva er sannsynligheten for at et svar med lengde $n$ er korrekt, om vi antar at sannsynligheten for å velge et feil ord er uavhengig? Hvis vi igjen bruker sannsynligheten for riktig ord = \(S\), kan vi uttrykke dette i \eqref{eq:prob-wrong} 5.
\[\begin{equation} P(\text{riktig tekst}) = S^n \label{eq:prob-wrong} \end{equation}\]Hvis vi skal generere en tekst med 250 ord. Da må vi først huske at hvert ord gjennomsnittlig tilsvarer rundt 4 tokens. La oss så si at modellen vår velger riktig token med en sannsynlighet på 99.9%. Da kan vi finne sannsynligheten for riktig tekst slik: \(P(\text{riktig tekst}) = (\frac{99.9\%}{100.0\%})^{250 \cdot 4} \approx 36.8\%\). Altså er det tilnærmet 37% sannsynlighet for at vi generer den helt riktige teksten, selv med en ekstremt høy sannsynlighet for å velge riktig token i hvert forsøk.
Men husk at modellen vår er i en feedback loop. Det betyr at sannsynligheten for å velge feil ord ikke er uavhengig i hvert steg, slik vi la til grunn for beregningen over. Sannsynlighetsfordelingen for ord påvirkes av de tidligere ordene som ble generert, siden disse nå er en del av teksten som brukes for å generere neste ord. Så om vi velger feil ord et sted i teksten, vil neste ord ha større sannsynlighet for feil enn om vi ikke hadde valgt feil ord. Ordet etter der vil ha enda større sannsynlighet osv. Dette fører til at vi vil oppleve at sannsynligheten for at teksten vår blir feil øker eksponentielt med lengden av teksten.
Dette er et stort problem som stammer helt tilbake til hvordan vi trente modellen i pre-training steget. Husk at i pre-training steget trente vi modellen til å forutsi neste ord. Men hvordan vet vi, som trener modellen, hva det mest sannsynlige ordet er? Ettersom vi kjenner hele setningen, så sier vi bare at det mest sannsynlige neste ordet er det ordet som faktisk står som neste ord i setningen. Og ikke nok med det. Vi sier også at dette ordet har 100% sannsynlighet, og at ingen andre ord er sannsynlige i et hele tatt. Det er jo en veldig merkelig tilnærming. La oss si at vi bruker setningen: “Jeg gikk en tur på stien.” som et treningseksempel til modellen. Vi fjerner ordet “stien” og modellens oppgave er nå å forutsi det mest sannsynlige ordet, gitt “Jeg gikk en tur på” som kontekst. Er det rimelig å si at “stien” er det eneste mulige alternativet her? Er ikke “veien” eller “fortauet” eller en hel del andre ord også ord som burde få en viss sannsynlighetsprosent? Ved å trene modellen til kun å tro at “stien” er det eneste riktige ordet, lærer den ikke en reell sannsynlighetsfordeling over alle ordene i vokabularet sitt, men en svært “biased” fordeling som, i dette tilfellet, prioriterer norske sanger alt for høyt.
Ettersom alle dagens språkmodeller er trent på denne måten, lider også alle av slike biaser. Vi har heller enda ingen god måte å løse det på. Foreløpig er det eneste man gjør å trene på ekstremt mye tekst, og satse på at vi får så mange forskjellige eksempler at modellen lærer seg noe som ligner på en rimelig sannsynlighetsfordeling. Personlig, tror jeg faktisk ikke vi vil være i stand til å løse det. Jeg tror rett og slett vi fundamentalt må endre måten vi trener modellene våre på, fra pre-training og hele veien opp.
Lærer modellen hva som er sant?
Den oppmerksomme leseren har antakelig merket seg at sannhet og faktuell riktighet ikke er en eksplisitt del i noen av treningsstegene vi bruker for å lage en god språkmodell. Man kan imidlertid argumentere med at alignment stegene implisitt lærer modellen å foretrekke fakta over usannheter. Dette fordi treningseksemplene i fine-tuning kan antaes å kun inneholde faktuelt riktige svar, mens mennesker foretrekker faktuelle svar i RLHF. Det er et godt poeng, men det er ingen garanti. For eksempel blir ikke feilen større i fine-tuning steget, dersom modellen ikke bare skriver feil tekst, men også kommer med usannheter. Det er derfor ikke verre for en modell å generere feil tekst med riktig betydning, enn det er å påstå åpenbare usannheter. Husk også at i vi i alignment trener en ekstra modell som en proxy for menneskelige preferanser. Denne proxymodellen er heller ikke eksplisitt trent til å foretrekke faktuelle svar, så man håper bare at fakta er en av preferansene den lærer seg når den etterligner menneskelige preferanser. Det er derfor ingen faktisk faktasjekk inkludert i noen av stegene når vi trener en språkmodell i dag. Hvorfor er det slik?
Svaret er ganske enkelt at vi ikke har muligheten til å sjekke sannhetsverdien i teksten modellen genererer. Grunnen til det er todelt. For det første, hvordan kan man automatisk sjekke at en tekst er sann? Vi har ingen robuste algoritmer som faktisk kan verifisere sannhetsverdien svarene fra en så generell modell som en språkmodell. Vi vil derfor i beste fall bare kunne gjøre en approksimasjon av sannhetsevaluering med f.eks. å holde en liste med gode kilder til sannhet, og deretter sjekke med denne listen, hvor mange av kildene som er enige med teksten modellen genererer. For det andre er slike faktasjekker uforholdsmessig dyre. De krever mye tid til søk og kildesammenstilling for å verifisere ett eneste faktautsagn. Som jeg nevnte i RLHF er det avgjørende at vi kan automatisere treningen og effektivisere hvert steg, ettersom vi må trene på en ekstrem mengde eksempler for å få en god modell. Det er rett og slett ikke økonomisk forsvarlig å gjøre en slik faktasjekking underveis i treningen i dag. Vi sier oss rett og slett fornøyde med å bruke en proxy for menneskelig feedback til å evaluere kvaliteten på et svar. Mer har vi ikke råd til.
Endringslogg
Under følger en endringslogg som viser hvilke deler av denne posten som er endret til hvilket tid. Enkle skrivefeil og den slags ting vil ikke bli logget, men jeg vil etterstrebe å logge alle meningsfulle endringer i posten.
- 2025-04-05: Endringslogg
- 2025-04-11: La til figurer
Referanser
Leviathan, Y., Kalman, M., & Matias, Y. (2023, July). Fast inference from transformers via speculative decoding. In International Conference on Machine Learning (pp. 19274-19286). PMLR. ↩︎
Hong, J., Lee, N., & Thorne, J. (2024). Orpo: Monolithic preference optimization without reference model. arXiv preprint arXiv:2403.07691. ↩︎
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., … & Guo, D. (2024). Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300. ↩︎
Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531. ↩︎
Yann LeCun: https://www.youtube.com/watch?v=xnFmnU0Pp-8 ↩︎